
このページはかなたそ模倣音声MLモデル、すなわちかなたそ版VOICELOIDを作るための実装について説明します。このパイプラインをたそネットと命名します。
このページの内容は専門的な内容であるため、特別興味のある人以外は読み飛ばす事を推奨します。特に面白くもないです。簡単に言うとシンプルな実装で舐めプして臨んだら迷宮知りして想定の5倍くらい時間がかかった、です。
次ページ(実践編)
データフローはこんな感じです
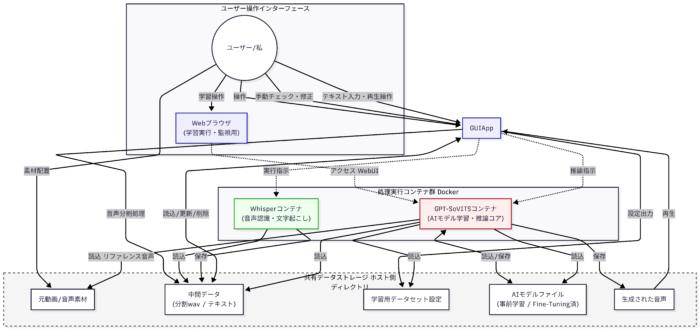
MLプロセス
まずこのNNの学習プロセスを分割すると下記のようになります
- 音声データ自動分割
- 発話内容の自動抽出
- 手動調整
- データセット成形
- GPT-SoVITSによるモデルFT
- 推論パイプライン整備
ざっとこんな感じです。音声データと会話内容の文字データの両方が求められるデータセットの特異性からデータ処理部分のプロセスが長めになっています。詳細は後述しますが言ったら有名モデルを自前のデータでFTしているだけなのですがこのせいで結構大変でした。
検討・設計
まずは方針の検討と設計です。他のNN設計のアプローチよろしく基本的には事前にトレーニングされたモデルが提供されているようです。おそらく現在出回っている模倣音声のほとんどがこれであると思うのですが、模倣先のリファレンス音声を推論の入力として使うゼロショット推論がメジャーなようです。
しかしいずれの場合も日本語音声の自然さを表現できるアーキテクチャやモデルは以外と多くなく、選択肢は限られます。
その条件下で選定したモデルがGPT-SoVITSです。基本的に中国語のモデルがメインのようですが、日本語のモデルの性能が聞いた感じこの手のゼロショット推論機の中で一番良さそうなのでこれを選定しました。
なお結果としてはゼロショット推論ではなく、事前学習モデルを自前のデータセットで再学習しています。ここのパイプラインを正しく動かし性能を出すのが一番難しかったですね。
1. 音声データ自動分割
まずデータセットを準備する必要があります。このデータセットは実際の配信から抽出された音声データとなります。結論から言うと結局ここが一番重要でした。しかもMLのお作法とは異なり量はあまりいらず、超絶高品質の音声を30-60分程度用意すれば十分です。
では超絶高品質な音声データとは何か?配信ではゲーム実況や雑談などありますが、ゲーム実況は当然ゲームのSEなどノイズが乗りまくりますし発声も不明瞭です。雑談配信や同時視聴配信でもバックグラウンドBGMが邪魔だったり発声があいまいだったりであまり機能しないことが多いです。では何を使うか?
謝罪配信です。
謝罪配信であれば、基本的に事前に用意したテキストの読み上げになるので発声も不明瞭です。ふざけたBGMも当然かかりません。なので、謝罪配信のデータを集めるのがあるスタートラインとなります。
その後データを10秒前後に再整形し、無音などの抽出を実施します。ここはPythonの音声編集ライブラリを使いました。一つアドバイスですがこういう試行錯誤を繰り返す系の処理はGUIを準備してしまうのが便利です。よっぽど出ない限りCUIとGUIでは操作性と情報量に差がありすぎます。
ここまでのプロセスを完了すると各セグメントごとに分割されたwavファイルが指定プロセスに出力されます。
2. 会話文字起こし
前プロセスで処理した音声ですが、このままだと音声だけです。学習に使うためには実際に何を喋ったかのテキストファイルが必要です。ここは結構コケるかなと思ったのですが、現代のAIは凄くて綺麗なデータセットを用意すれば結構ちゃんと文字起こししてくれます。たそネットではOpenAIのWhisperを使っていますが、ML関連ライブラリ周りの依存がだるかったのでGUIからDockerコンテナを実行していく形で実装しています。
これを実行するとこんな感じのテキストファイルが出ます。

3. 手動調整
ここまで見たらわかるようにところどころデータにおかしいところがあります。データセットの質はモデルの質にクリティカルに効いてくるので、全て手動で精査します。これも専用のGUIツールを作って行います。
ひたすら手動で修正していくだけです。
4. データセット成形
これはGPT-SoVITSに必要なデータ入力形式に変換するだけです。割愛します
5. GPT-SoVITSによるモデルFT
案の定と言うかここでとにかくコケました。依存がかなり多くてしんどいのと、必要な事前学習済モデルと設定用ファイルとの対応付けが僕には明瞭ではなく苦戦しました。僕は自前で実装したかったので自分のDockerfileを作りましたがあまりにもコケる箇所が多かったので大人しく提供されるDockerとWeb Interfaceを使ったほうが良いです。configがそのままじゃ動かなくて自前で変数を用意したりする必要が出てきます(少なくとも僕は)。
まず結果的にできたGUIを見てください。
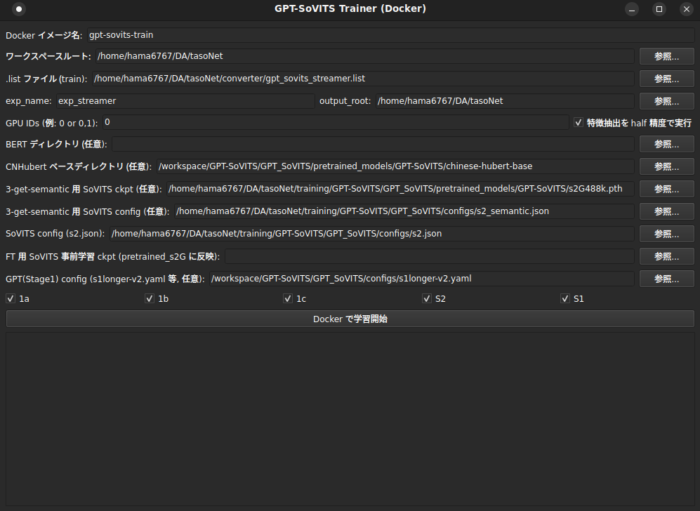
地獄のような設定項目があります。このパイプラインは単一のモデルで学習されているわけではなくいくつかのモデルにパイプラインは分割されており、それぞれ必要な事前学習モデルと設定ファイルを読み込ませる必要があります。当然ですがここを完璧に対応させないとうまく行きません。
うまくいけばやっと学習です。FTだけならそんなに重くないですし、あまり学習させすぎるとノイズが乗るので体感2-3 epochで十分です。CPUでも十分できると思います。後述しますが、ここでは完璧なモデルを目指すより推論時に使えるレベルのモデルのバリエーションを増やしておくことが実務上役立つと思います。元モデルは中国語用ですがなんか割とうまく行きます、GPTモデルがニュアンスを掴むためのトークンを出してるらしいのでそれがうまく効いてるっぽいです。すごい。

6. 推論
やっと推論まで来ました。生成モデル全体に言えるのですが、結局やることは賢いランダム生成(暴論)なので、推論を実施するモデルとリファレンス音声をいくつか用意し、全ての組み合わせで生成しもっともそれっぽいものを最終版として使うのが良かったです。
推論に必要な情報は
- FT済モデル
- レファレンス音声データ
- レファレンス音声データのテキスト
- 読み上げたいテキスト
です。この辺をうまく処理する仕組みを作ると良いです。レファレンス音声というのは、推論のときに入力として取る話者の音声データで、モデルももちろんそうですがこのリファレンス音声に近いニュアンスで音声が出力されます。このリファレンス音声は10秒程度のデータ1つで良いです。なので理論上はモデルそのものをFTしなくても事前学習済モデルを使えば話者の音声で出力されるというのがウリですが、それだとやはりやや微妙な仕上がりになります(比較は次ページ)。ですがリファレンス音声の雰囲気にかなり寄せられるので、色々準備しておくと色んなニュアンスの音声を出力できるようになります。
最終的なGUIがこれです。
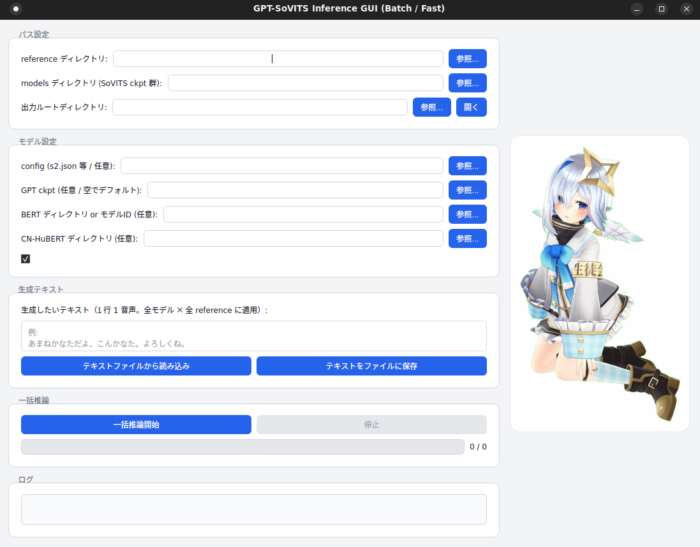
ポイントが、ディレクトリの中に入っているモデルとリファレンス音声、テキストを全て読み込み、その全ての組み合わせで推論を実施するようになっていることです。これにより声が明るいバージョン、多めにFTしたモデル、控えめなモデル、などバリエーションが生まれ自分の意図したニュアンスの出力が得られやすくなります。
ただ、GUIの実装をPyside6でやったのは失敗でした。Dockerで使うならWebベースのフロントエンドを使ったほうが良いです。同じコンテナ内で素直に動作します。結局推論だけまた環境分けてvenvを作る羽目になってしまいました、学習用のコンテナまでわざわざあるのに…
たそネットパイプラインは数日ここにおいて起きますが後述の理由であんまり良くないので数日で閉鎖予定です。あとコードがカオスでDockerとはいえあんまり再現性がないです。参考程度に
https://github.com/hama6767/tasoNet
いずれにせよ、これで準備完了(ここまで20時間)です!かなたそ、待っててね…
次ページは実践編です。